快速开始 #
为了更好的保证用户体验,建议使用Google浏览器进行操作。
在使用过程中有任何疑问或建议,可以【扫码添加客服微信】获得支持。想使用SD-WebUI/comfyUI/炼丹的用户,可移步"镜像/AI应用专区"

1. 上传数据到网盘 #
平台为每个用户都分配一个网盘,登录后点击控制台,在左侧导航栏就能找到网盘入口。
用户可以在浏览器完成上传文件,上传文件夹,删除文件等基本操作,针对大文件,强烈建议使用命令行工具。
每个用户的网盘都是隔离的,底层采用分布式存储技术,可以保证极高的数据可靠性。
每个新用户,平台会赠送10GB大小的存储空间,超过10GB需要按容量进行收费。收费标准参见充值和计费。
如果您在上传和下载时遇到问题,请参见这里的小技巧
2. 创建工作空间 #
点击算力市场,可以看到平台上提供的算力资源。按照计费方式,可以分为按量付费资源和包月资源。这两个的区分是:
- 购买按量付费的资源后,会帮用户自动创建一个工作空间(安装指定镜像的容器开发环境),平台会按小时进行资源计费。只要用户没有手动停止,该实例会一直运行。
- 购买包月资源后,不会自动创建工作空间,已购的资源会出现在控制台-我的资产-我的算力中。包月资源在购买时进行扣费,到期后会自动释放。
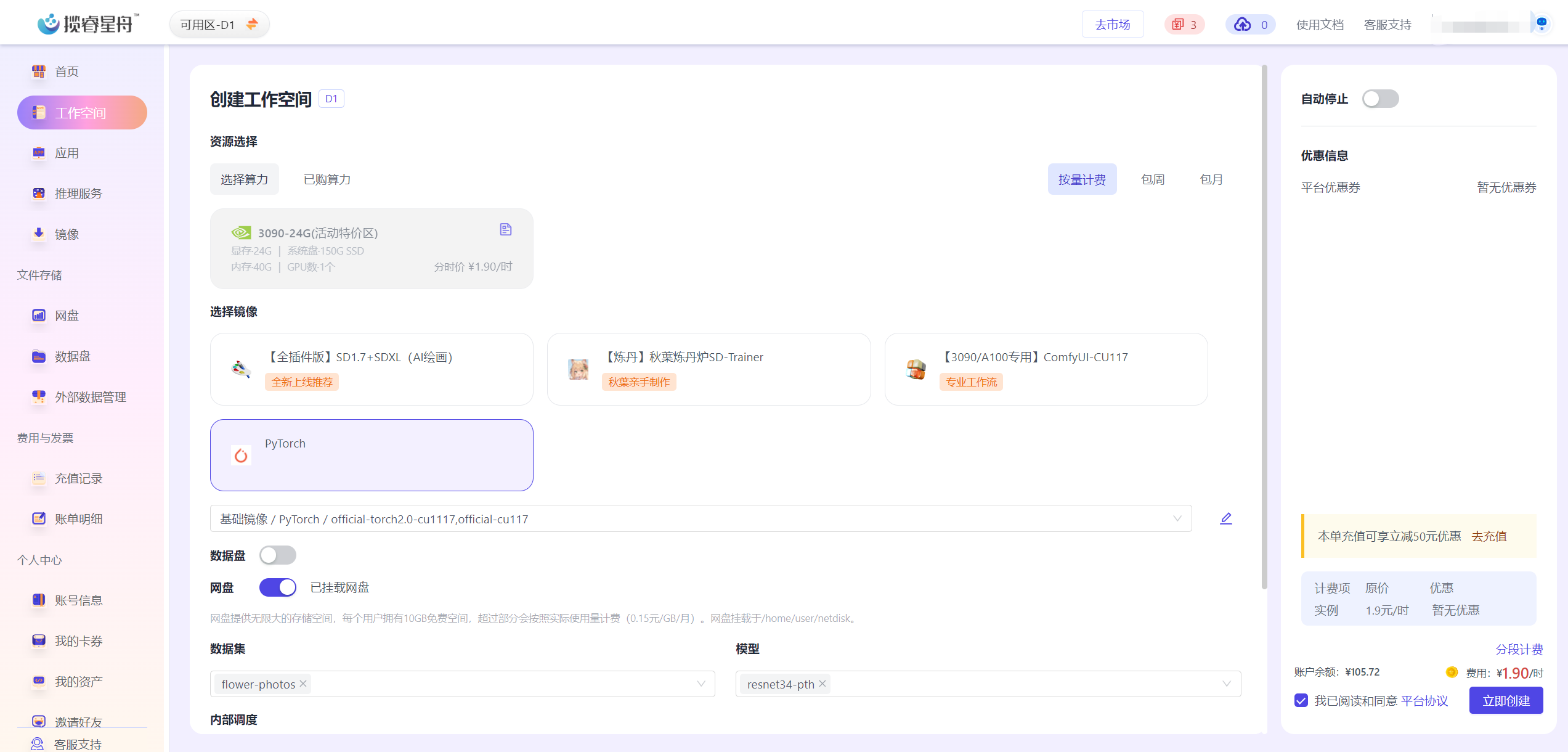
这里我们选择按量付费的资源,点击使用,然后选择一个pytorch镜像,用户可以选购买数据盘(当前支持200G,500G两种规格),可以加载平台数据集,模型,并设置自动停止时间。如果无需这些设置,直接点击创建实例即可。
为了后续的例子,我们加载数据集flower-photos,加载模型resnet34-pth
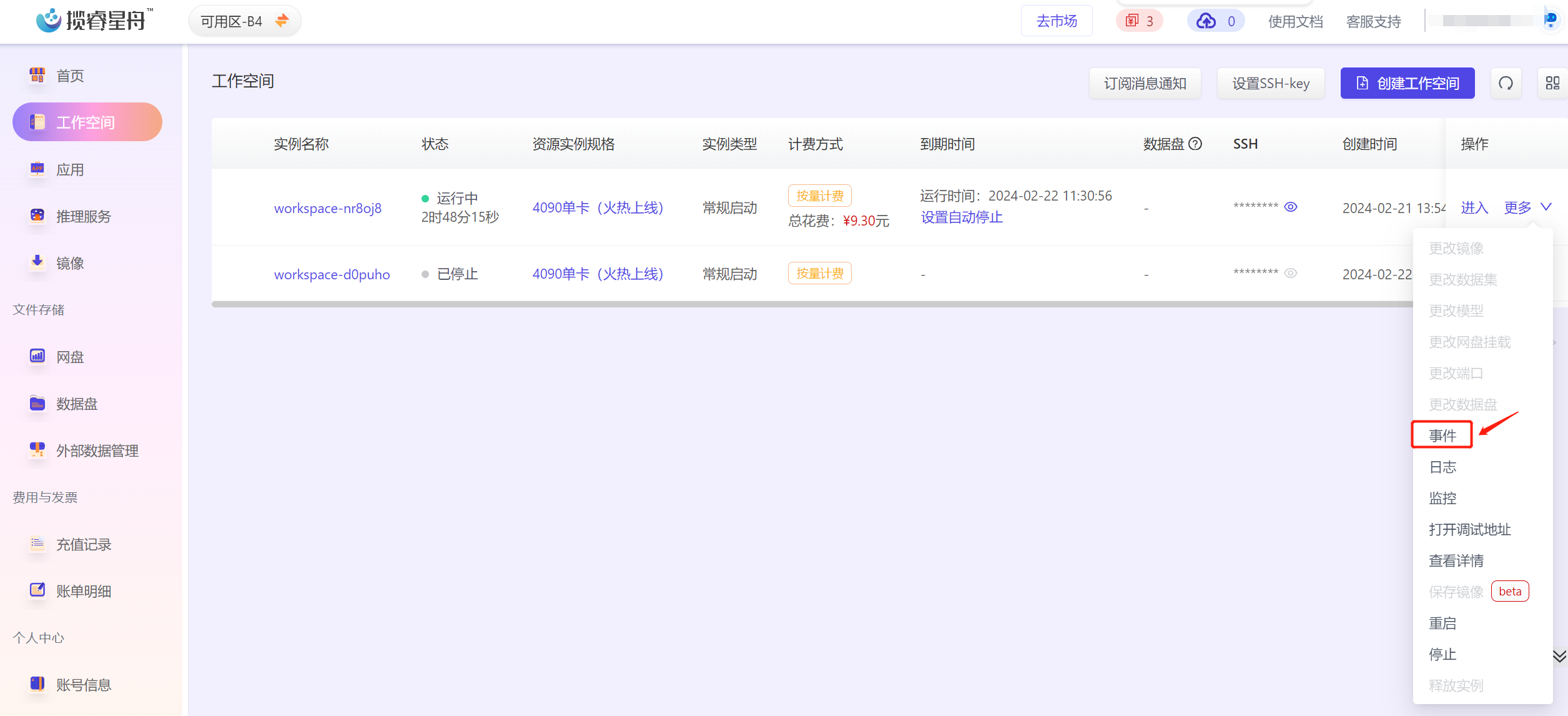
在工作空间列表页面,可以看到刚才创建的工作空间,待状态变为运行中时,就可以正常使用了。在启动过程中如果遇到问题,可以点击操作栏的事件按钮,会在屏幕下方显示事件窗口,查看相关信息。事件窗口的右上角可以切换高级模型,显示更详细的错误信息。
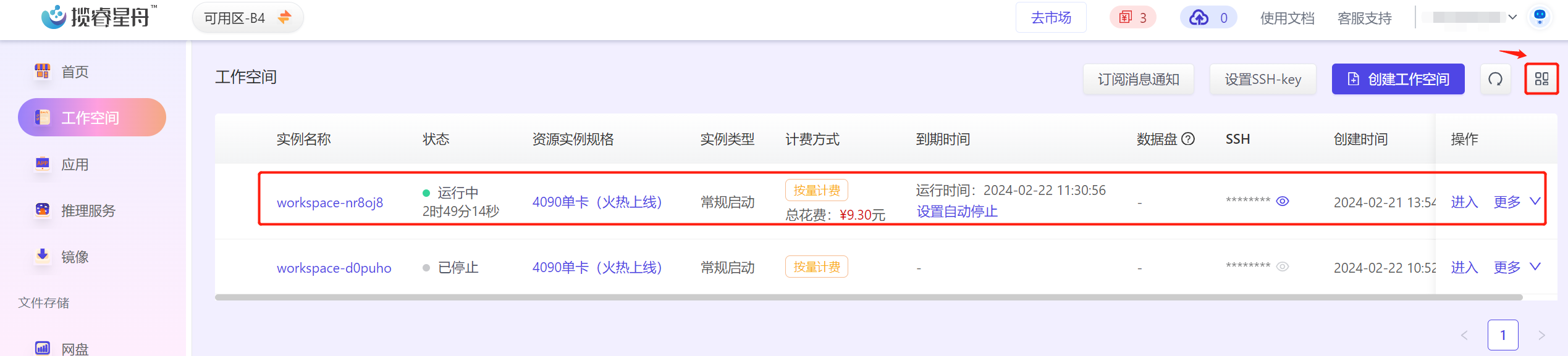
点击操作栏的“进入”按钮,选择Jupyter或者VSCode打开工作空间,也可以在SSH列点击星号后面的小眼睛,就可以显示SSH登录命令,复制粘贴到个人电脑终端中进行登录(注意使用SSH登录的前提是先在平台上传了SSH pubkey, 这块的介绍参见这里)
2.1 文件系统 #
工作空间中几个重要的文件系统说明如下:
- /home/user/datadisk,该目录是工作空间的数据盘,会持久化到块存储上,工作空间停止或者重启后,数据不会丢失,除非用户手动释放工作空间。
- /home/user/netdisk/data,该目录是网盘的data文件夹,是在多个实例之间共享的,可以当成NAS来使用,但读写速度会比数据盘慢一些。
- 该路径与原路径/ark-contexts/data一样,均可作为网盘路径使用,建议后续网盘data读写路径使用/home/user/netdisk/data - 如果在启动工作空间时挂载了数据集,数据集会放在/home/user/imported_datasets/目录下,该目录是一个只读目录。
- 如果在启动工作空间时挂载了模型,模型会放在/home/user/imported_models/目录下,该目录是一个只读目录
- 根目录/,该目录是工作空间的数据盘,显示为500G,但实际可用空间为150G(其他空间被系统占用),实例关闭或者重启后,数据会丢失。请尽量不要写系统盘,特别的不要写满系统盘,否则会引起实例异常重启!
3. 开始训练 #
3.1 准备工作 #
在工作空间中,我们可以使用nvidia-smi命令查看显卡信息。
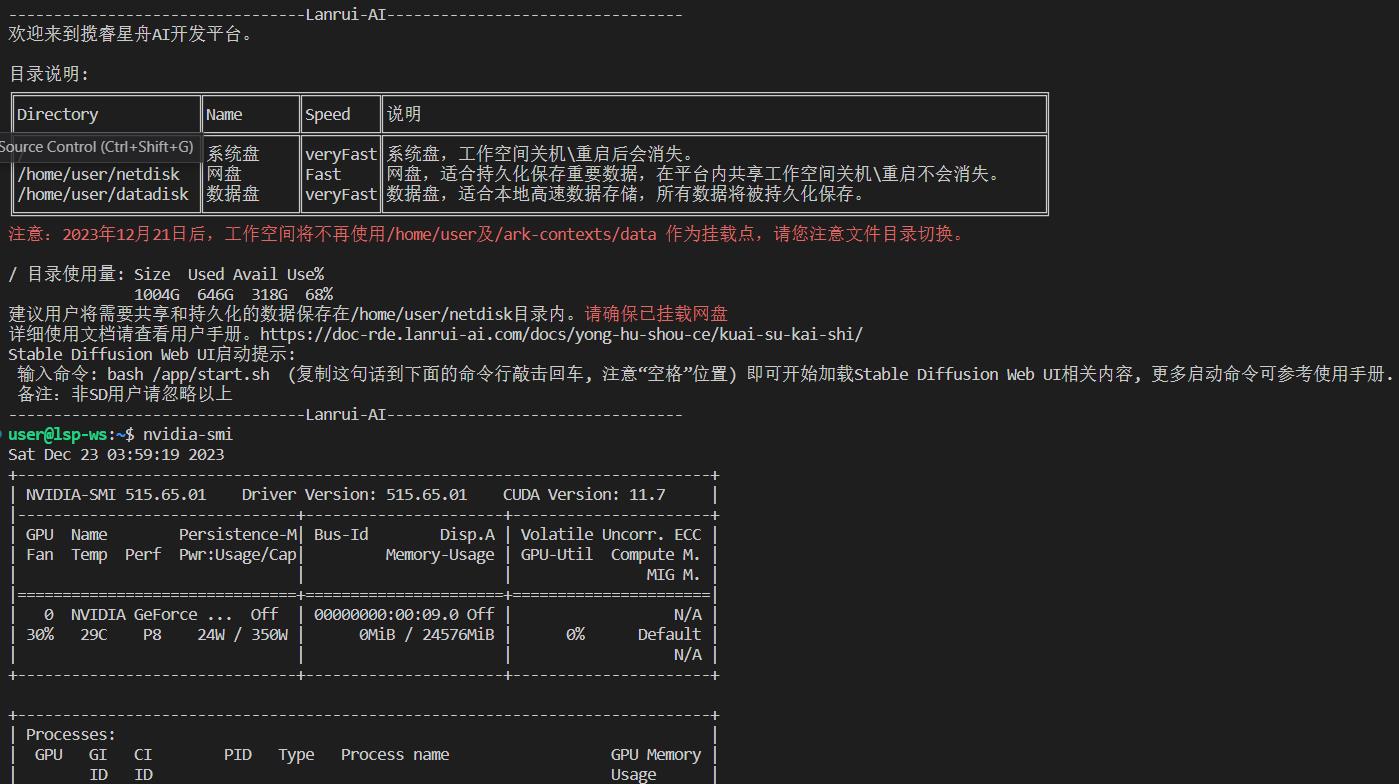
可以看到HOME目录是在/home/user目录,该目录下有一个data目录,会默认挂载网盘中的data目录。同时HOME目录下会出现imported_datasets和imported_models两个目录,里面有刚才设置的数据集和模型。

我们以github上的这个例子进行说明
git clone https://github.com/WZMIAOMIAO/deep-learning-for-image-processing.git
注意:如果发现git clone慢,请参考这里进行加速
3.2 训练模型 #
我们来复现pytorch_classification/Test5_resnet这个项目,按照说明,这个项目会使用resnet34网络对flower_photos数据集进行迁移学习。
首先,我们按照项目要求,将数据集复制到deep-learning-for-image-processing/data_set目录并进行训练集和验证集的划分
cd ~/deep-learning-for-image-processing/data_set
mkdir -p flower_data/flower_photos
cp -r ~/imported_datasets/flower-photos/* flower_data/flower_photos
python3 split_data.py
进入pytorch_classification/Test5_resnet项目目录,按照说明,把resnet34这个模型拷贝到该目录下,并执行train.py脚本
cd ~/deep-learning-for-image-processing/pytorch_classification/Test5_resnet
cp ~/imported_models/resnet34-pth/resnet34-333f7ec4.pth resnet34-pre.pth
python3 train.py
默认epoch=3,可以看出,因为使用了resnet34预训练的权重,第1轮epoch,准确率就能达到94%。

我们可以对train.py做一点修改,不使用预训练模型,而是从头开始训练resnet,如下图我们注释掉部分内容,并修改epoch为20,重新训练(python3 train.py)
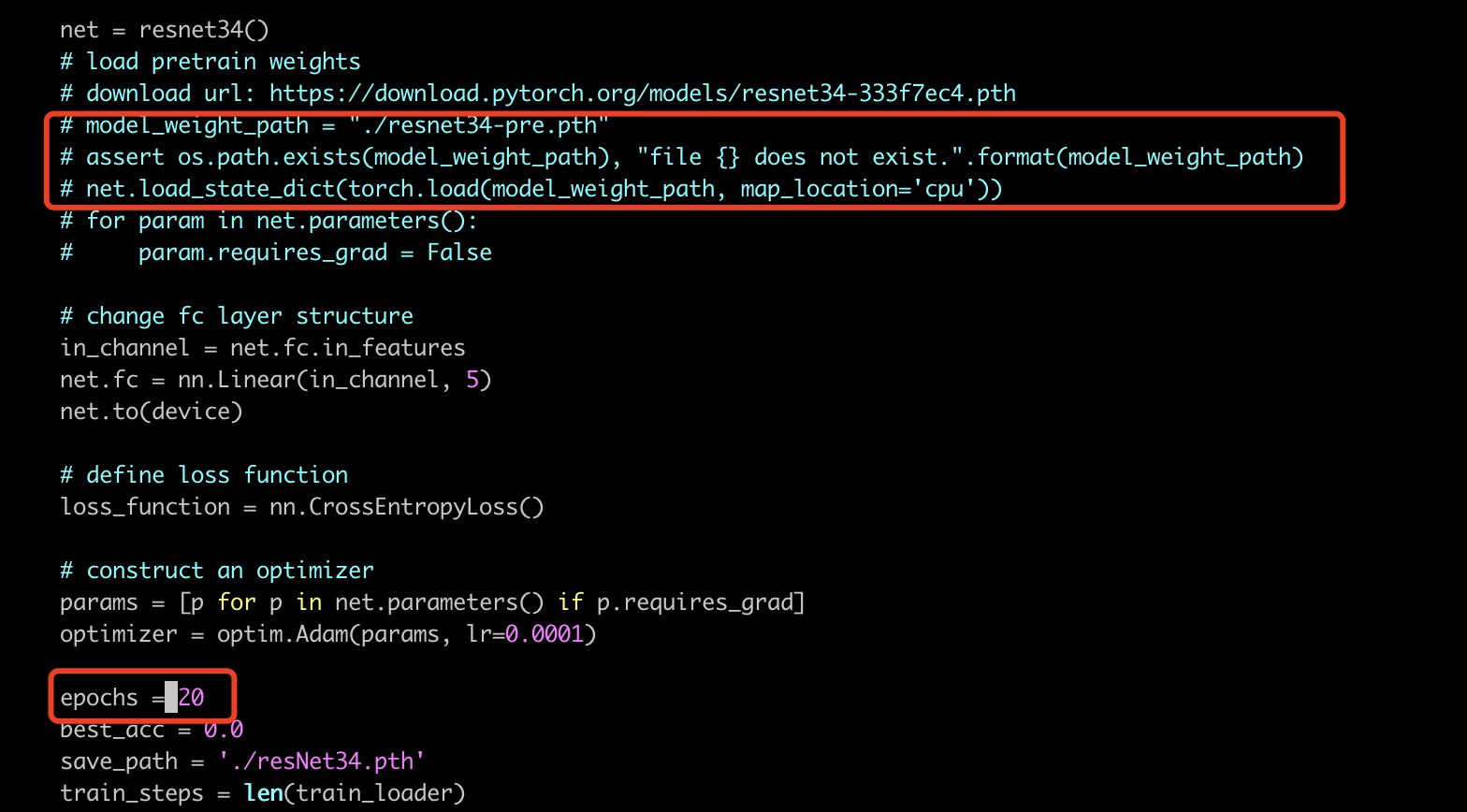
可以看到,不使用迁移学习时,经过20轮后,准确率也只有79%

在训练过程中,我们可以使用平台提供的监控功能,打开grafana查看GPU,CPU的运行状况
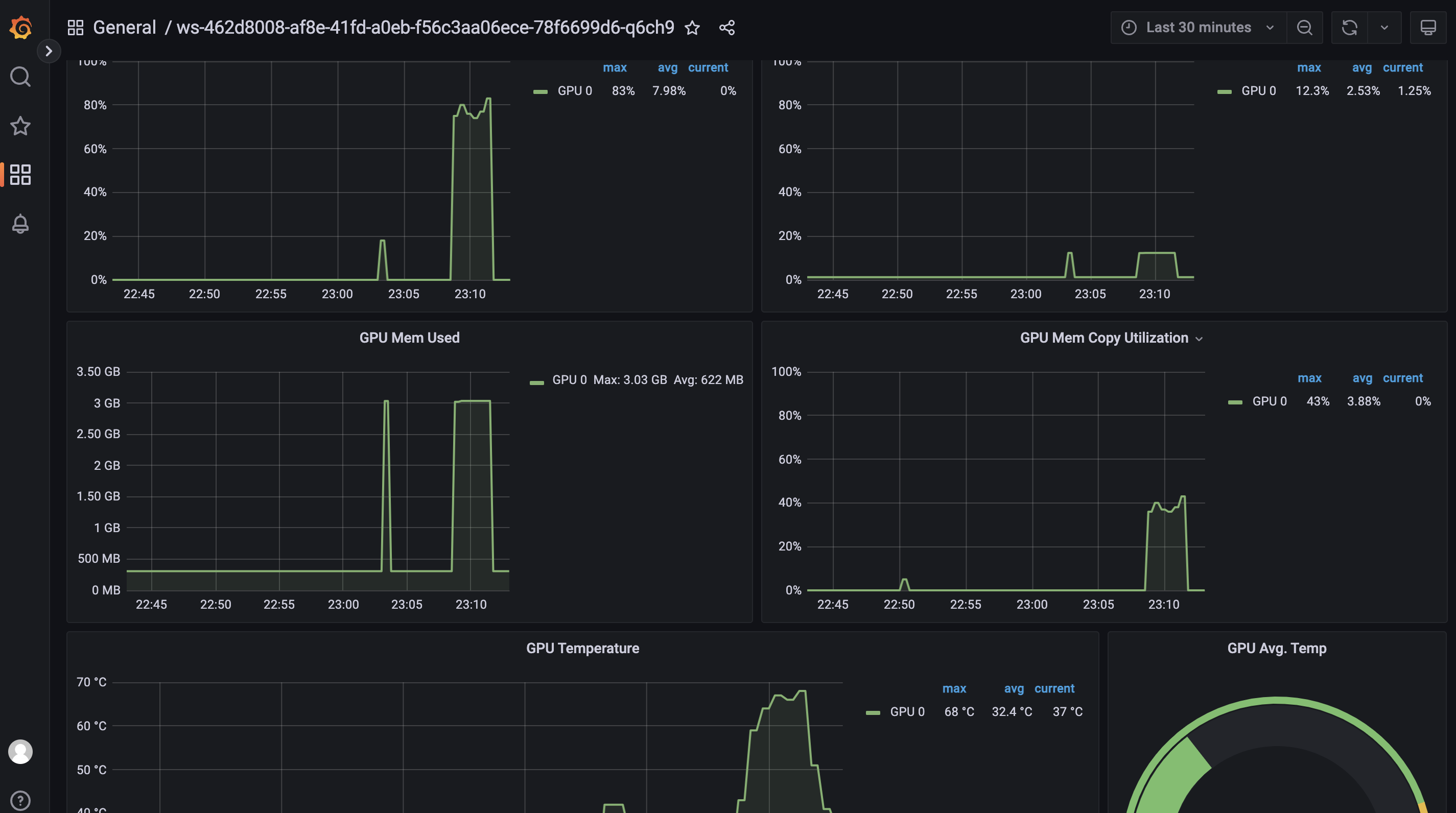
4. 应用启动器 #
目前平台已经提供了SD WebUI/Fooocus/ComfyUI启动器,都支持一键启动快速部署。