kohya_ss训练LoRA教程 #
揽睿第一期直播嘉宾-蕃茄
项目地址:https://github.com/bmaltais/kohya_ss
训练前准备 #
图片要求 #
- 20~100张1:1的图片,尺寸最好是像素512512或者10241024的,如果想训练出来的效果质量好一点,推荐1024*1024的;数量几十张即可;
- 分辨率适中,勿收集极小图像;
- 数据集需要统一的主题和风格的内容,图片不宜有复杂背景以及其他无关人物;
- 图像人物尽量多角度,多表情,多姿势;
- 凸显面部的图像数量比例稍微大点,全身照的图片数量比例稍微小点。
图片网站:
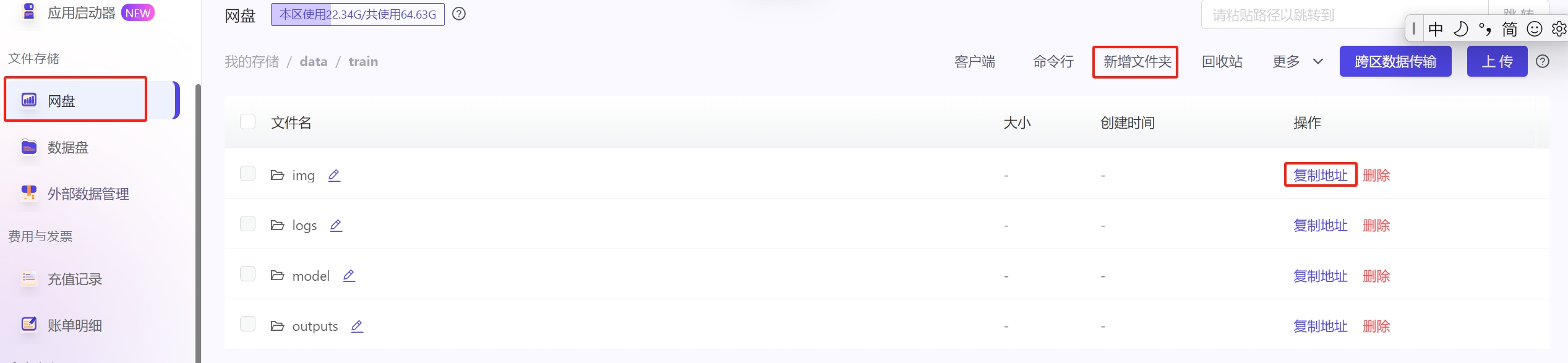
准备素材上传到网盘 #
进入网盘data,新建文件夹train,再新建二级文件夹分别为img/outputs/model/logs/的文件夹。
该文件夹路径为/ark-contexts/data/train/XXX,点击「复制地址」按钮即可复制完整路径。
点击网盘右侧的上传文件夹上传自己的数据集,若文件数量较多可通过小黄鸭或者命令行上传;
-
img文件夹:放训练的数据集。上传图片文件夹命名格式为:“xx_XXXXX”,其中xx是数字,代表训练步数,XXXXX为自定义名称,例如30_cat
-
outputs文件夹:模型保存目录
-
model文件夹:放训练用的底膜(快速上传模型方法)。
-
logs文件夹:日志文件夹
一. 创建工作空间 #
- 进入工作空间页面,点击创建工作空间,选择自定义创建;
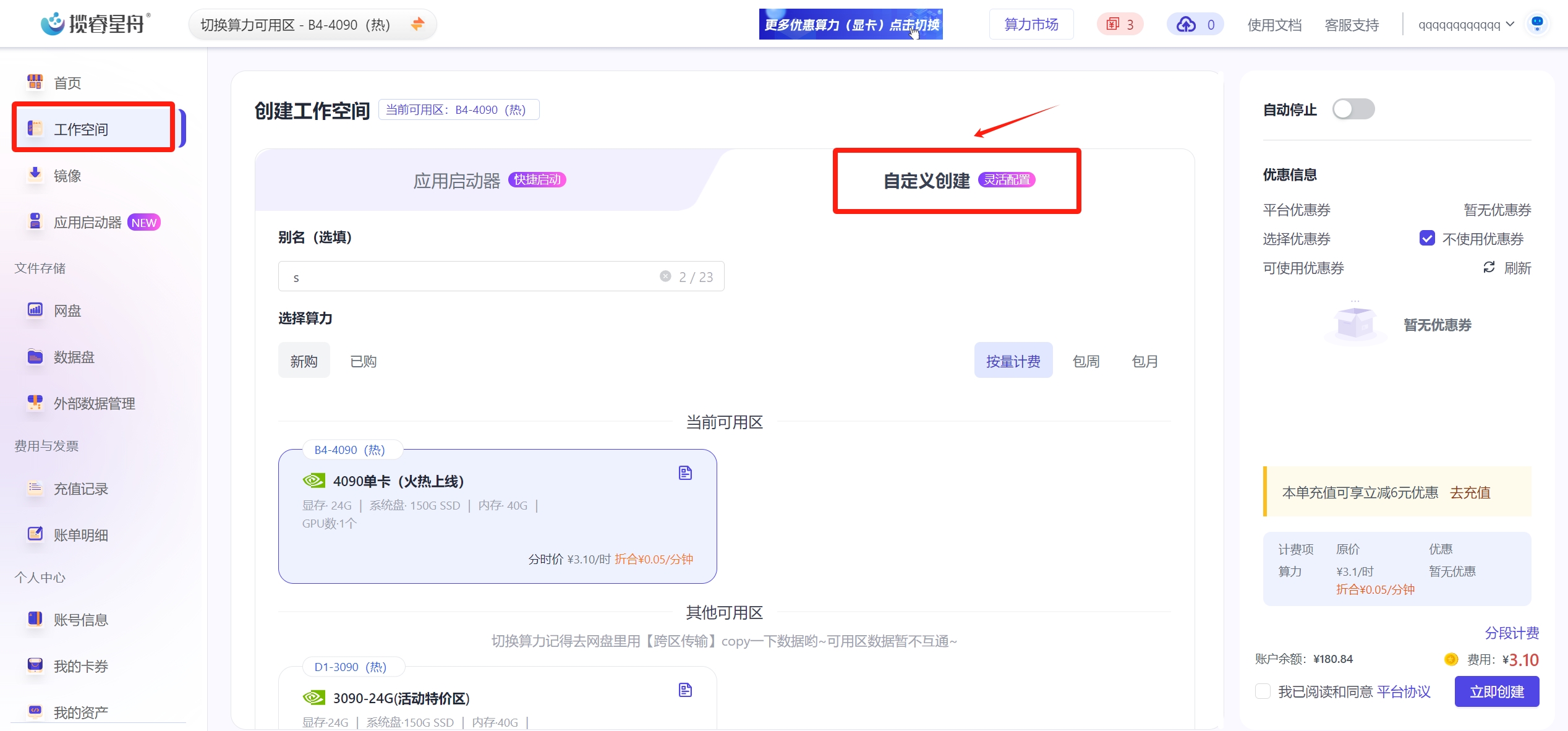
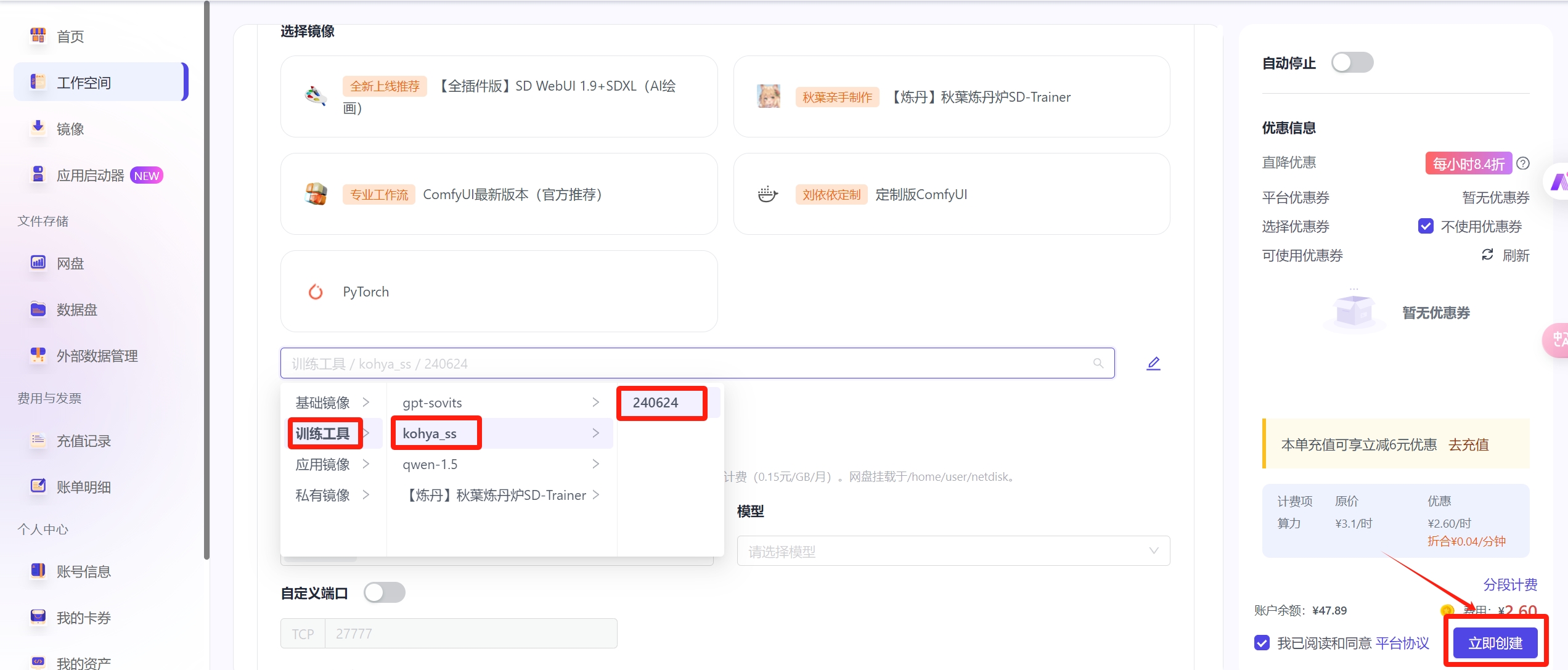
- 选择4090或3090算力,选择镜像训练工具/kohya_ss;网盘默认挂载,数据集默认挂载sd-base;点击立即创建
二. 启动工作空间 #
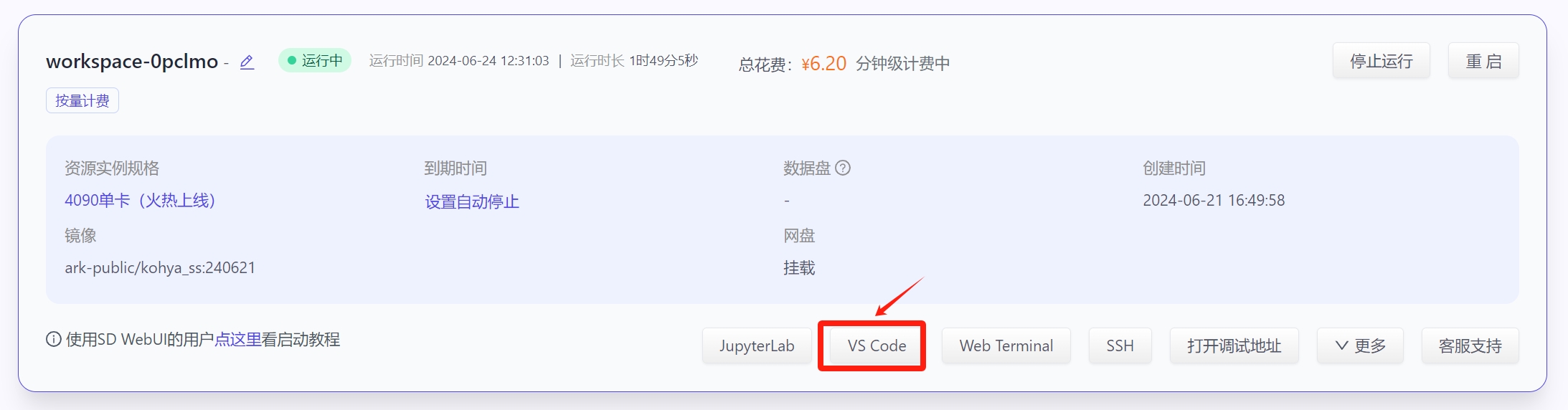
点击创建后,一般1-2分钟可启动成功,待实例状态由启动中变为运行中后,点击进入vscode
三. 启动kohya_ss #
进入vscode后,点击【打开文件夹】,输入/home/user/后点击OK,选择信任,最后我们在左侧栏就能看到目录文件。
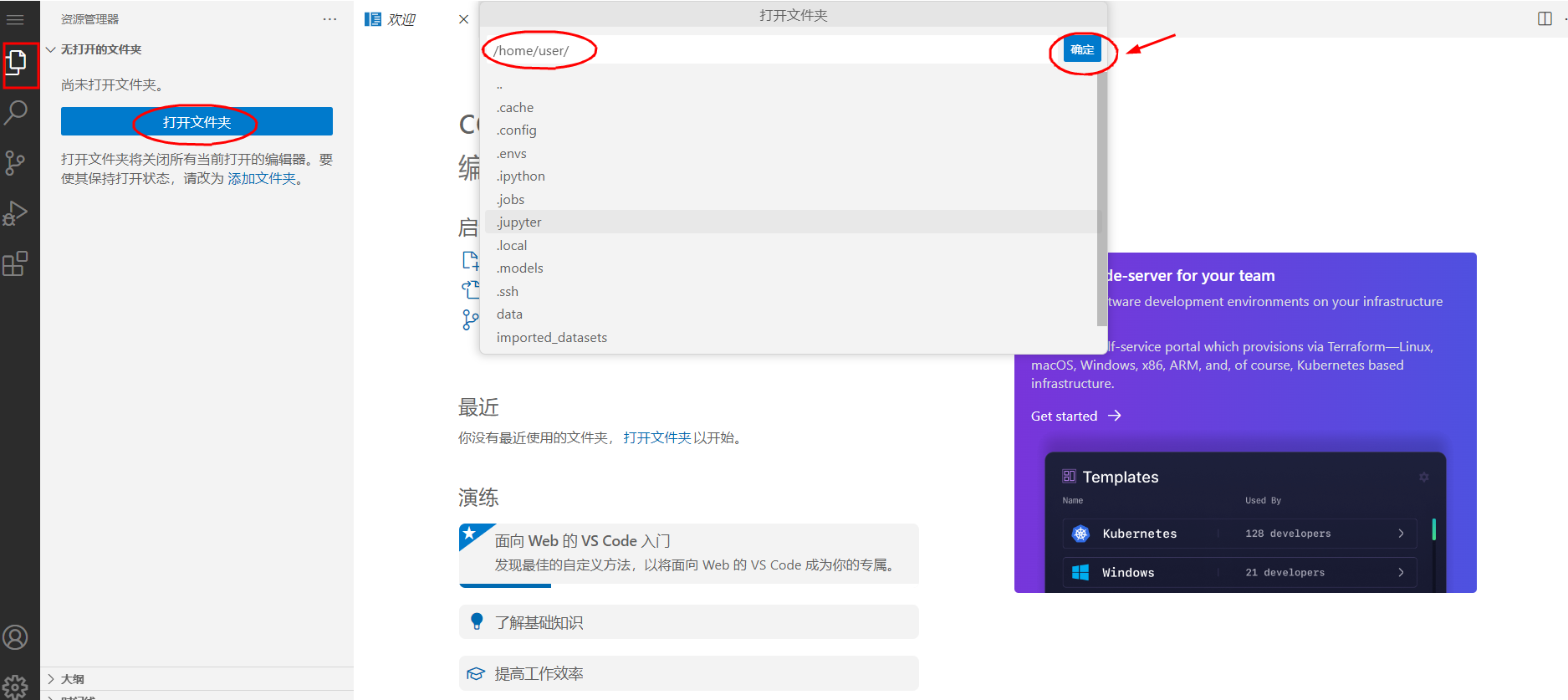
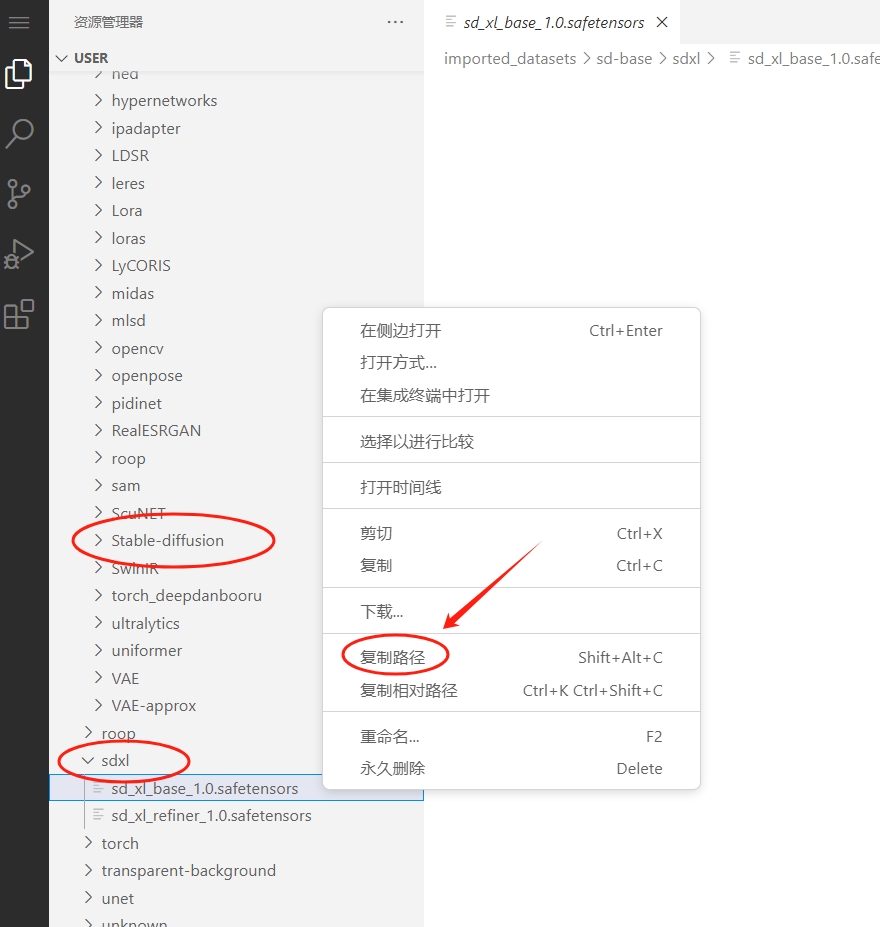 平台内置了常用的模型,如果您需要使用sd-base数据集中的模型作为训练底模文件等,可以找到模型后右键单击【复制路径】可获取模型完整路径,下面训练时候会用到这个路径,需要特别记住一下。
平台内置了常用的模型,如果您需要使用sd-base数据集中的模型作为训练底模文件等,可以找到模型后右键单击【复制路径】可获取模型完整路径,下面训练时候会用到这个路径,需要特别记住一下。
- sd底模路径:
/home/user/imported_datasets/sd-base/models/Stable-diffusion/模型文件名称 - sdxl模型路径:
/home/user/imported_datasets/sd-base/sdxl/模型文件名称 - VAE模型路径:
/home/user/imported_datasets/sd-base/models/VAE/模型文件名称
2、点击左上角新建terminal终端
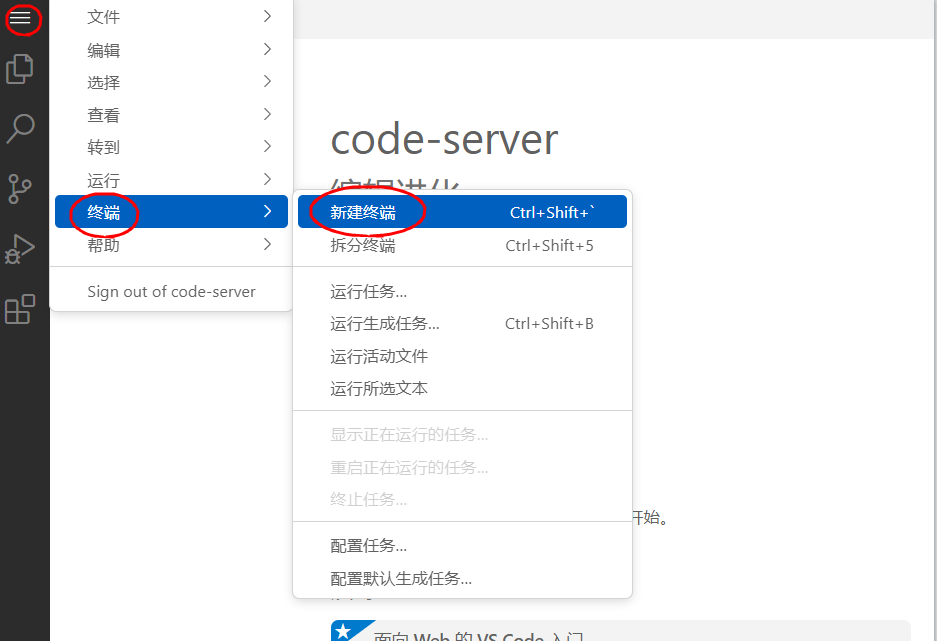
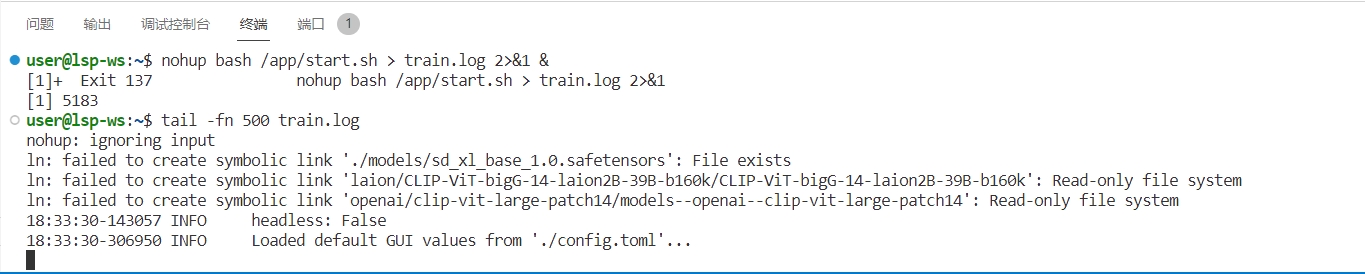
运行以下启动命令,然后按回车键;
nohup bash /app/start.sh > train.log 2>&1 &
启动/训练进度输入以下命令查看:
tail -fn 500 train.log
运行结果如图所示,即可进入kohya_ss页面进行打标/训练。(如图所示)
如果您在训练中想要停止重新训练,可输入以下停止命令,然后重新运行启动命令:
pkill -9 -f '27777'
四. 图片预处理 #
点击打开调试地址,进入kohya_ss页面;
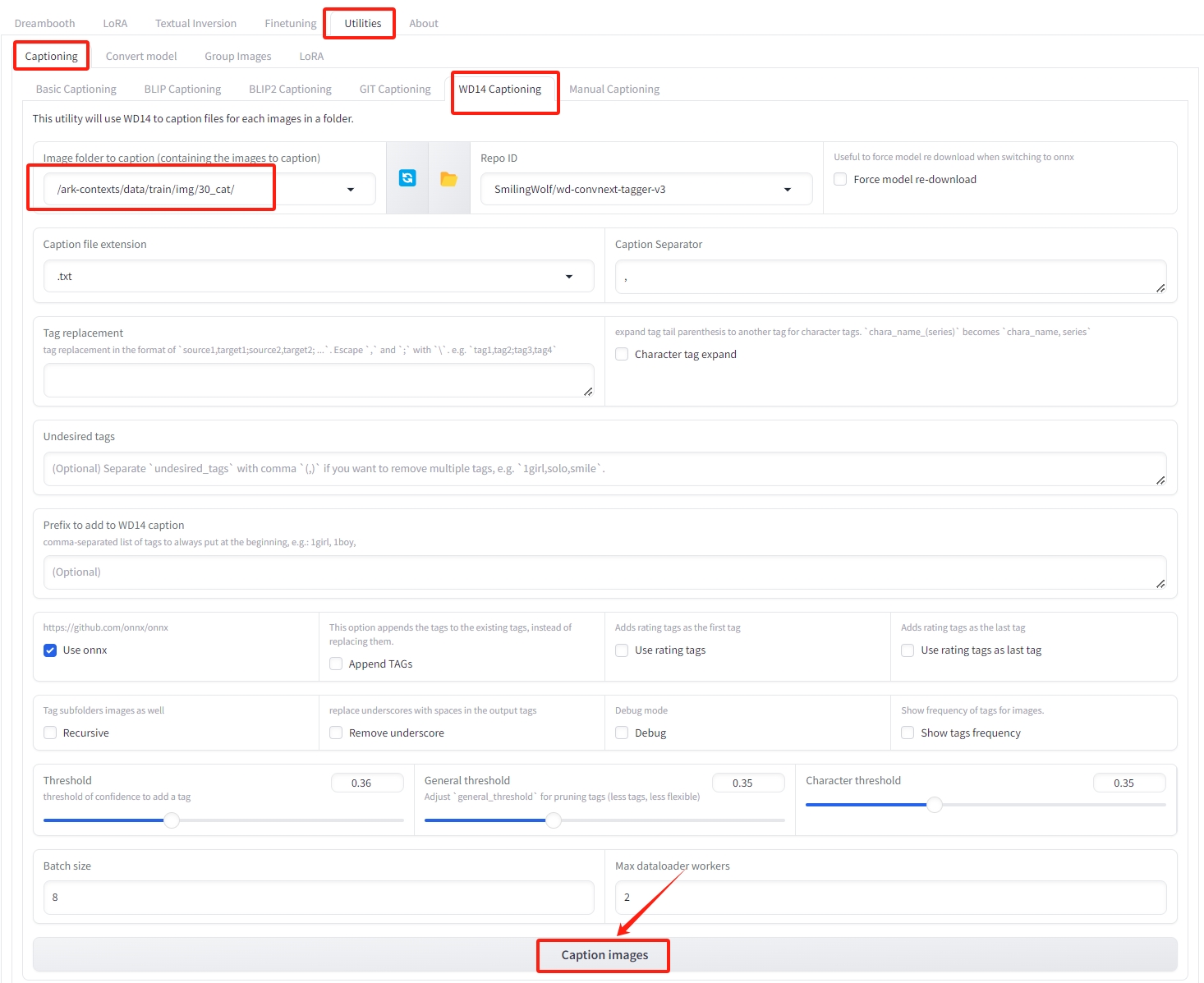
点击Utilities→WD14 Captioning,复制数据集地址到Image folder to caption下,点击Caption images,等待打标完成。
如上面提到上传的文件夹为30_cat,地址为/ark-contexts/data/train/30_cat
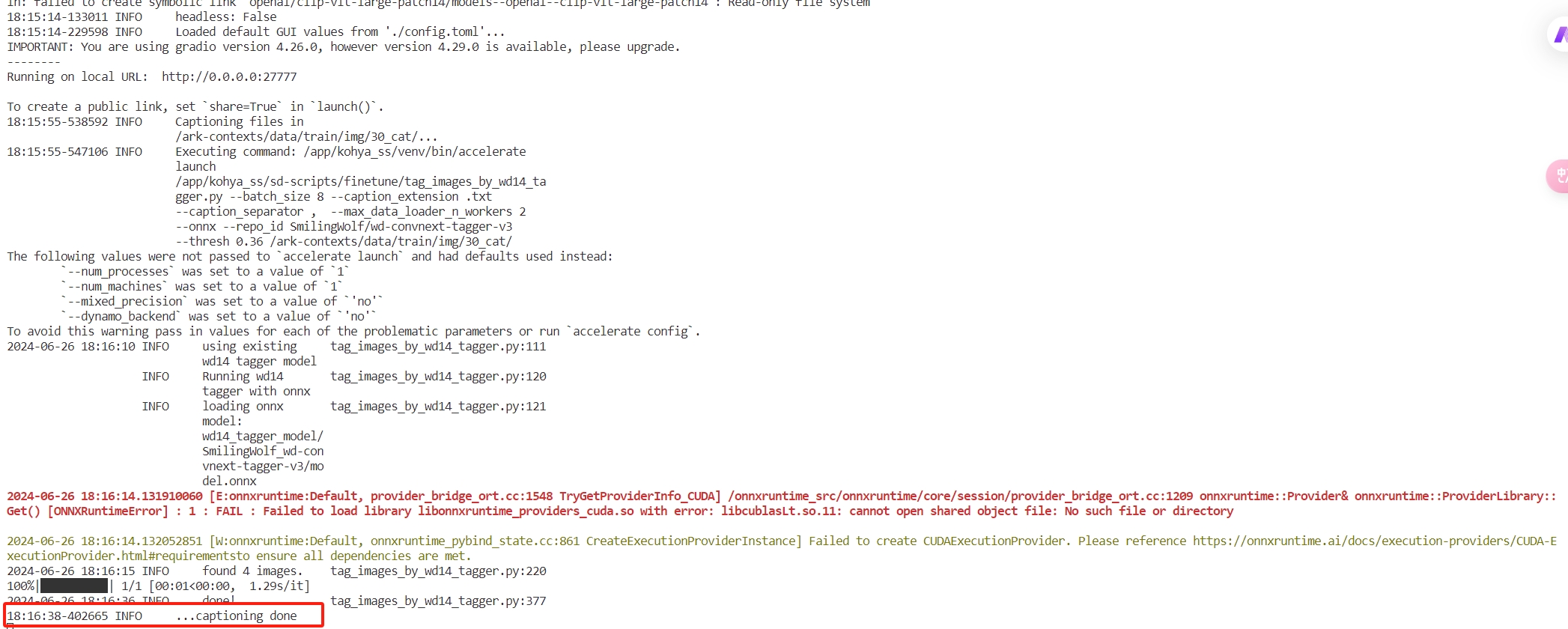
训练好,在原来的图片文件夹就是一张图片一个文本,这样我们的图片预处理就结束了
五. 开始训练 #
第一步:选择训练底模lora→Training→Model; #
Pretrained model name or path(训练底膜路径):使用sd-base数据集中的模型,或用自己上传的底膜路径。如果是二次元就用二次元的主模型,真人的就用真人系的模型。 我这里用的是sd-base数据集自带的sdxl底膜,路径为/home/user/imported_datasets/sd-base/sdxl/sd_xl_base_1.0.safetensors
Trained Model output name(生成模型名字):按需修改
Image folder(数据集目录):/ark-contexts/data/train/img/
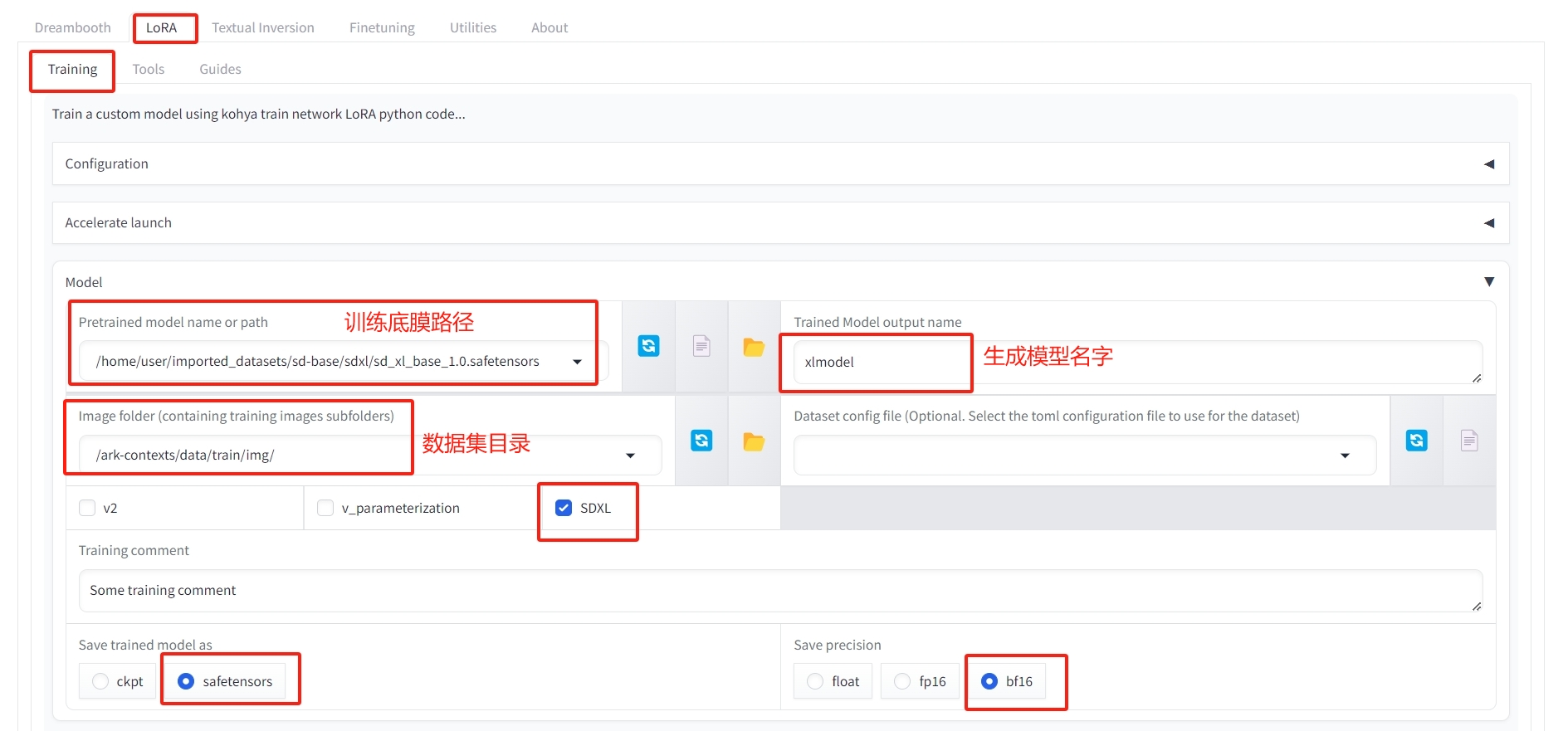
注:如果底膜是sd1.5的底模,取消勾选sdxl
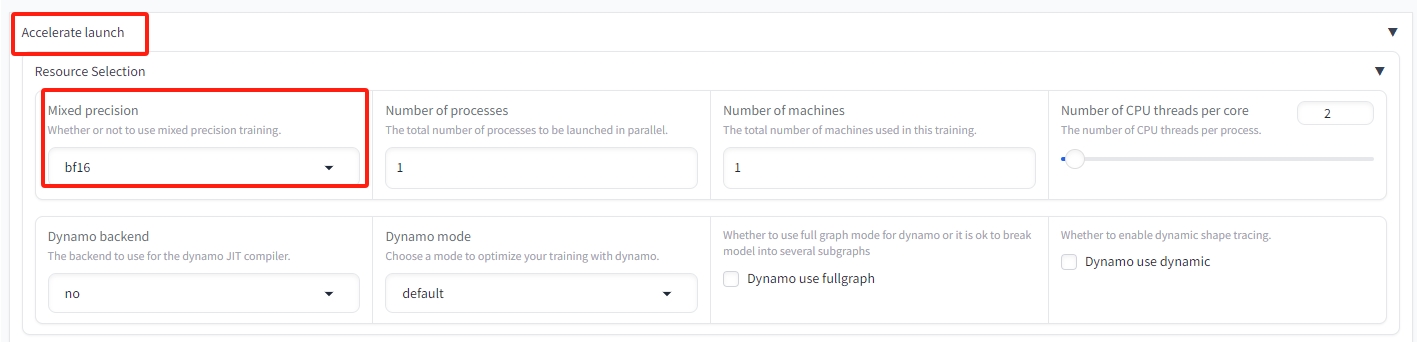
混合精度选择bf16:Accelerate launch→Mixed precision→选择bf16
第二步:配置输出目录lora→Training→Folders #
以下输出目录必须修改
Output directory for trained model(模型输出目录):/ark-contexts/data/train/outputs/
Logging directory(日志输出目录):/ark-contexts/data/train/logs

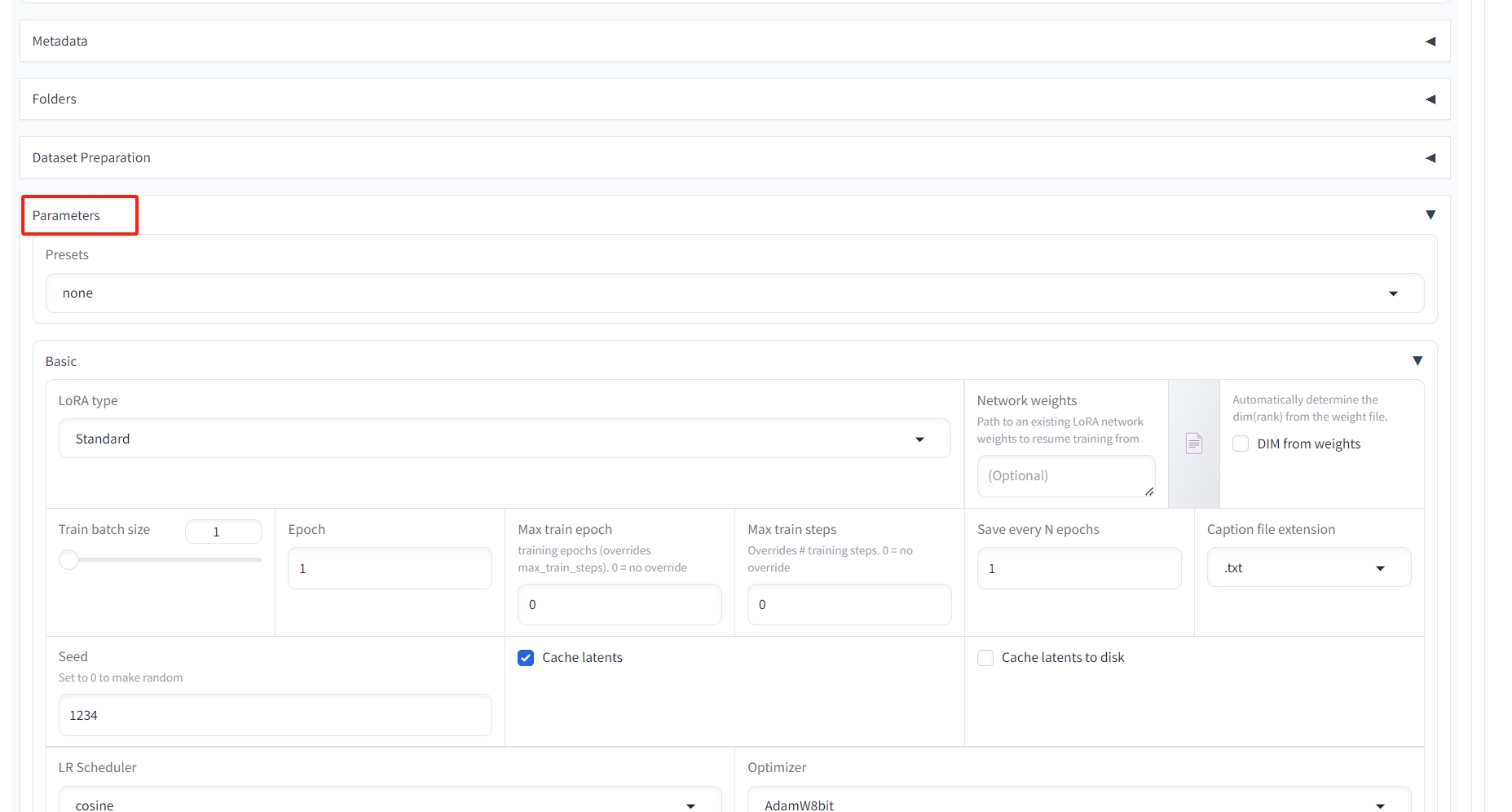
第三步:Parameters配置训练参数 #
kohya_ss提供了很多可以调节的参数,比如batch_size,learning rate等,可根据实际情况配置。
第四步:Start training提交训练 #
提交训练,可在终端查看训练进度
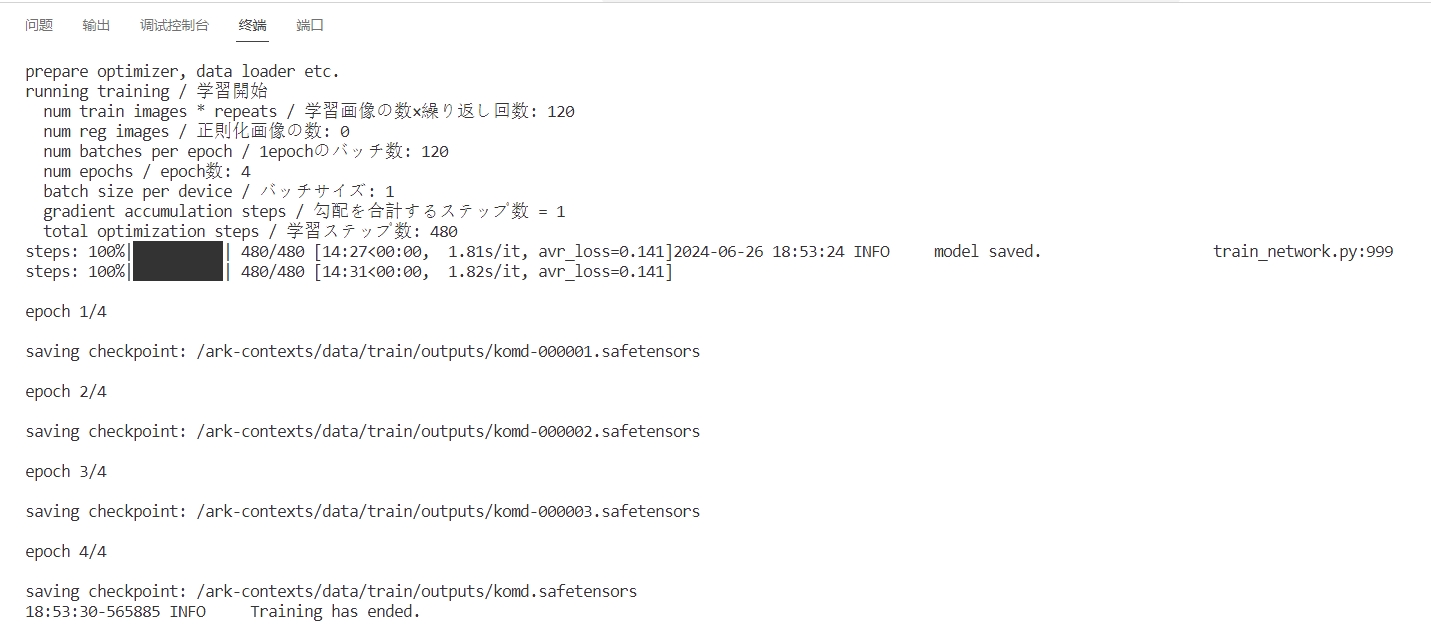
提示训练完成后,在您之前创建的data/train/outputs 文件夹即可找到您的模型.
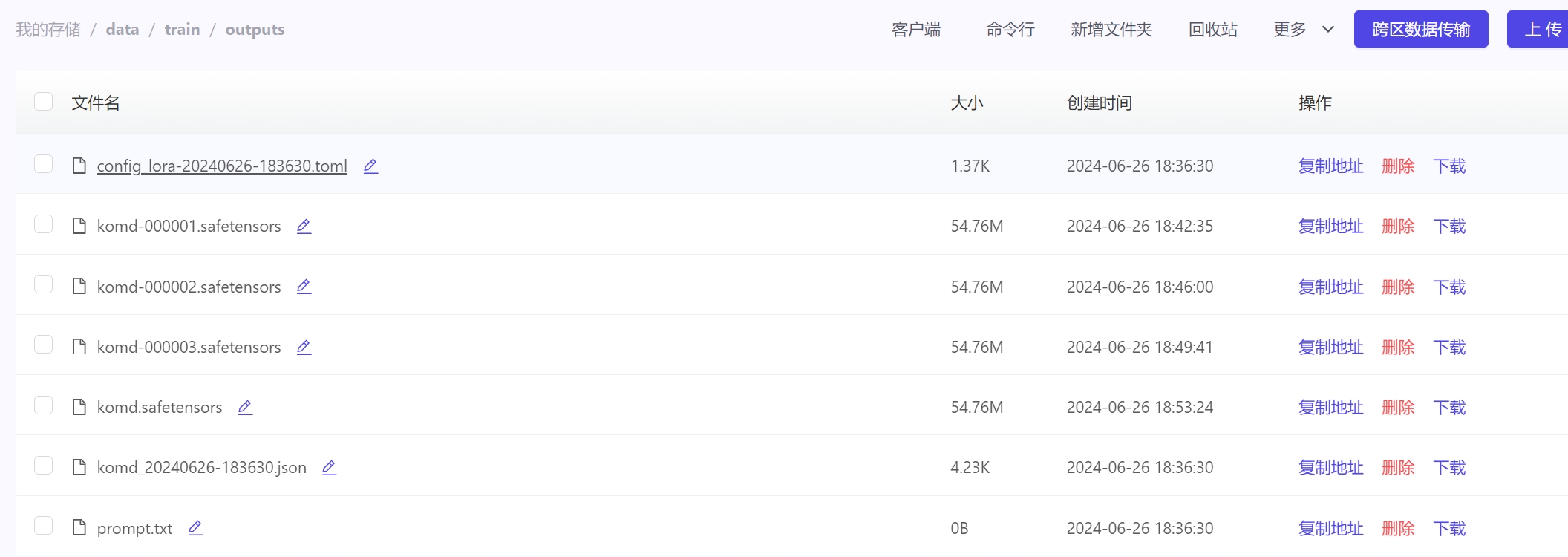
通过文件管理功能传输到Stable Diffusion Web UI的网盘data/sd-4/models/Lora目录就可以使用啦!
训练总步数公式 #
训练前我们需要知道一个训练总步数的公式:
Total Steps=RepeatImageEpoch/Batch_size //训练总步数=每张图片的重复次数(训练步数)图片数量训练轮次÷批量大小(并行数量)
Image:很好理解,也就是准备的图片集文件夹中图片的数量,一般为20-50张。
Epoch:训练的轮次,也就是所有图片训练完为1轮,从头在训练2轮、3轮……,这里一般建议训练5-10轮。
Batch_size:并行数量、批处理大小,也就是一次处理几步。数值的多少取决于你的电脑显卡显存的大小,显存小(6G及以下)推荐写1,乖乖的一次只处理一步;显存大的显卡(12G及以上)可以根据情况而定,可以写2-6。当然并行处理的步数越多,则LoRA训练的速度越快!讲到这里也就不难理解上面公式为啥要除以batch_size这个数。
参数设置
Batch_size,并行批处理个数、一次处理的步数,根据自己显存大小来设置,显存小写1,显存大可以写2到6。
Epoch,训练的轮次,一般写1到10。
Save every N epochs,写1则每训练一轮便保存一次LoRA模型,比如:如果前面Epoch设置5轮,这里写1,则最后训练完成可以得到5个LoRA模型。
Network Rank(Dimension)维度,代表模型的大小。数值越大模型越精细,常用4~128,如果设置为128,则最终LoRA模型大小为144M。一般现在主流的LoRA模型都是144M,所以根据模型大小便可知道Dimension设置的数值。设置的小,则生成的模型小。
Network Alpha,一般设置为比Network Rank(Dimension)小或者相同,常用的便是Network Rank设置为128,Network Alpha设置为64。
Max resolution,训练图片的最大尺寸,根据自己图片集的最大分辨率填写。如果图片集里的图片分辨率大小不一,可以勾选右边的“Enable buckets 启用桶”
学习率和优化器的设置
Optimizer(优化器),默认会使用AdamW8bit(下面会讲其他几个优化器),在AdamW8bit优化器时,学习率的设置参数如图所示。
Learning rate(学习率),可以理解为训练时Ai学习图片的速率。学习率大,则训练的快,但是容易“一目十行”,学的不够细致精确。反之,学习率小,则训练的慢,但是学的比较细致精确。默认值为0.0001,也可以写为1e-4。
Unet learning rate(Unet扩散模型学习率),设置此参数时则覆盖Learning rate(学习率)参数。默认值为0.0001,也可以写为1e-4。
Text Encoder learning rate(文本编码器学习率),一般为Unet learning rate的十分之一或者一半,比如设置为5e-5(1e-4的一半则为5e-5,十分之一则为1e-5)。
LR Scheduler(学习率调度器),理解为训练时候的调度计划安排,默认为constant(恒定值),常用cosine_wite_restarts(余弦退火)。
余弦退火算法(Cosine Annealing)是一种常用的优化算法,它是一种让学习率从一个较大的值开始,然后以余弦函数的形式逐渐减小的算法。它可以帮助模型更快地收敛到最优解,且具有良好的优化性能。此外,余弦退火算法还可以更好地改善模型的泛化能力,即模型在未见过的数据上的表现。
“Training parameters训练参数”高级设置
如上图,这里面需要设置的部分不多。
Keep n tokens(保持N个tokens),这个参数是用来设置触发词数量的。在前面提示词打标的时候,你为你的LoRA模型设置了几个触发词,这里就填写几,常见的有1~3。
Clip skip,二次元模型选2,写实模型写1即可。
“Training parameters训练参数”采样图片配置
Sample every n steps,比如设置为100,则代表每训练100步采样一次。
Sample every n epochs,每N轮采样一次,一般设置为1。
如上设置之后,LoRA训练的同时会每隔设定的步数或轮次,生成一副图片。